

Ser uma empresa orientada a dados é o que todas as organizações precisam e estão perseguindo cada vez mais

Poder fazer qualquer pergunta sobre os dados do negócio que já aconteceram (análise descritiva);
Obter previsões do que deve acontecer com o negócio (análise preditiva), e
Obter explicações sobre o peso dos fatores que justificam as previsões para terem insights sobre o que precisa ser feito (análise prescritiva).
Todo esse esforço para gerar insights que orientem a descoberta de importantes forças, fraquezas, oportunidades e ameaças é para a rápida elaboração de planos de ação para poder aproveitar a situação ou se defender dela.
Não é possível dizer que uma organização, privada ou pública, é completamente “não data driven” ou totalmente “data driven”. Nem tampouco se pode ir de um estágio “não data driven” para “data driven” de um salto só.
Na verdade, esse é um processo contínuo e iterativo como num ciclo PDCA onde a cada giro executado com sucesso se pode dizer que estamos caminhando para uma posição mais data driven do que antes.
A realidade dos dados nas organizações atualmente apresenta algumas barreiras para que o movimento data driven possa ocorrer com suavidade. Vamos ver:
Esta fase normalmente é composta por um esforço misto entre área de TI, analistas das áreas finalistas (de custo, de orçamento, de marketing, financeiro, fiscal, de materiais, de produção, etc) e usuários finais de negócio.
Isso é um problema porque as transformações aplicadas sobre os dados para fazer limpeza, cálculos de indicadores, adaptações estruturais e criações de novas informações, acabam ficando espalhadas em vários lugares. A área de TI desenvolve scripts em SQL e gera bancos de dados, o que deveria ser o padrão.

Contudo, muitas planilhas eletrônicas ainda são geradas nas extrações de dados, ao invés de bancos de dados. Quando é assim, os usuários acabam criando novas colunas e aplicando novas regras de transformação nas planilhas por meio de fórmulas e macros.
Quando as planilhas são então usadas como fontes de dados nas ferramentas de visualização como Qlik, PowerBI ou Tableau, é comum a criação de novas transformações sobre os dados ou pela área de TI ou pelos próprios usuários de negócio.
A consequência desta forma de trabalhar é a dificuldade em se obter uma única versão da verdade. Torna-se muto comum que uma pergunta simples como “qual o faturamento do mês passado?” produza respostas com números diferentes trazidos por setores diferentes.
Outro ponto crucial que dificulta o caminho data driven de uma organização é o vocabulário limitado dos usuários quanto ao conhecimento de gráficos e o que eles estão comunicando. Desde a graduação, passando por cursos de especialização e MBA, normalmente trabalhamos com o famoso trio de gráficos Barra, Pizza e Linha. Fora disso, só a já tradicional Tabela ou Tabela Dinâmica.
Conhecendo apenas esses tipos de gráfico, perdemos uma gama bastante vasta de possibilidades de ler informação e relacionar coisas que estão presentes em um monte de outros tipos de gráfico, tais como Dispersão, Radar, Árvore, Cascata, Caixa, Treliça, Mekko, Nuvem de Palavras, Mapas Multicamadas, Acordes, Combinados, entre outros muitos que podem ser customizados.
O primeiro desafio aqui é o usuário conseguir ler o gráfico e entender que informações ele está comunicando. O segundo desafio é o próprio usuário montar aquele novo tipo de gráfico para expor suas descobertas. O desafio final é o usuário argumentar em favor de suas ideias usando o gráfico de forma dinâmica durante uma reunião. É bem similar ao aprendizado de uma língua estrangeira, onde é comum passar pelos níveis de leitura, escrita, fala básica e chegar na fala fluente. Sabemos que estamos fluentes naquela língua quando conseguimos participar de uma argumentação com várias pessoas.

A inspiração dos usuários de negócio é a planilha eletrônica. Ela foi a grande responsável pela introdução do microcomputador nas empresas e está presente há muitas décadas nas organizações. O modelo mental da planilha é o de primeiro conseguir todos os dados que eu preciso e carregar na planilha.
Feito isso, posso começar a filtrar, ordenar, transformar, calcular e ver dados de diversas formas, inclusive em gráficos diversos. Na hora de mostrar as análises e descobertas, montam-se slides para serem apresentados nas reuniões executivas. Este é o modelo utilizado há muito tempo.
Quando os usuários então conhecem uma ferramenta de Analytics moderna, como Qlik, PowerBI ou Tableau, a tendência é replicarem essa forma de trabalhar com a qual já estão acostumados. Isso significa que sempre partem de um conjunto de dados limitado que é extraído para se estudar um cenário específico.
Sobre esses dados limitados, são construídos então painéis de análise nas ferramentas de Analytics que imitam os slides antes utilizados. São painéis estáticos, com poucas possibilidades de filtros e que apresentam gráficos com os eixos X e Y pré-definidos e sem a possibilidade de troca (e.g. gráfico de barras mostrando as Vendas por Linha de Produto).

Quando os painéis estão sendo mostrados nas reuniões de gestão, sempre aparece aquela pergunta imprevista que fica sem resposta. A resposta é “Ops, esse dado nós não pensamos em trazer para esse cenário!”. A resposta fica então para a próxima reunião quando, muitas vezes, ninguém se lembra mais do que se tratava.
Fazer qualquer pergunta imprevista e obter respostas instantâneas é um dos principais indutores do data driven numa organização.
Por isso, a dinâmica utilizada atualmente não atende a este requisito.
Os usuários de negócio estão acostumados a correr atrás dos dados navegando pelos painéis de análise em busca de informações. São poucos que também conseguem receber algum feedback automático do ambiente de Analytics.


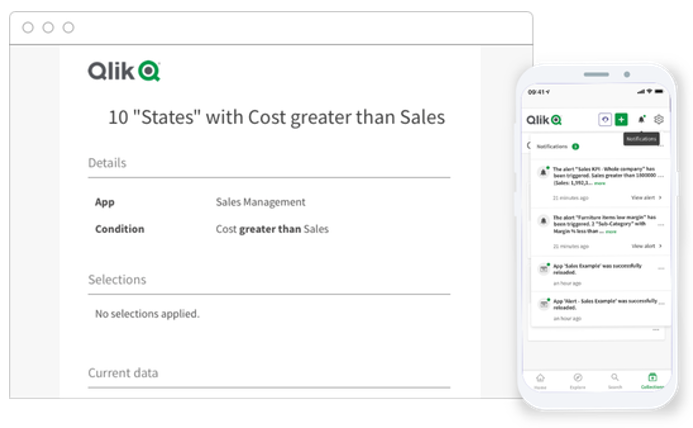
O ideal seria que o usuário pudesse, por exemplo, espalhar sensores pelos dados e receber alertas pelo celular todas as vezes que um dado sofresse uma modificação importante (e.g. avise-me sempre que a margem bruta da linha de produtos naturais na região Sul baixar de 10%).
Além dos sensores sobre os dados, também seria bom receber relatórios regulares via e-mail (e.g. envie-me o relatório de metas de vendas toda segunda, quarta e sexta às 9h da manhã). Imagine então se fosse possível receber predições sobre o comportamento futuro dos dados e explicações sobre essas predições também de forma automática (e.g. envie-me toda segunda-feira às 10h da manhã a lista de clientes que tem probabilidade de deixar a empresa e a lista dos principais fatores que contribuem para saírem).
Qual a solução da Toccato para mudar essa realidade?
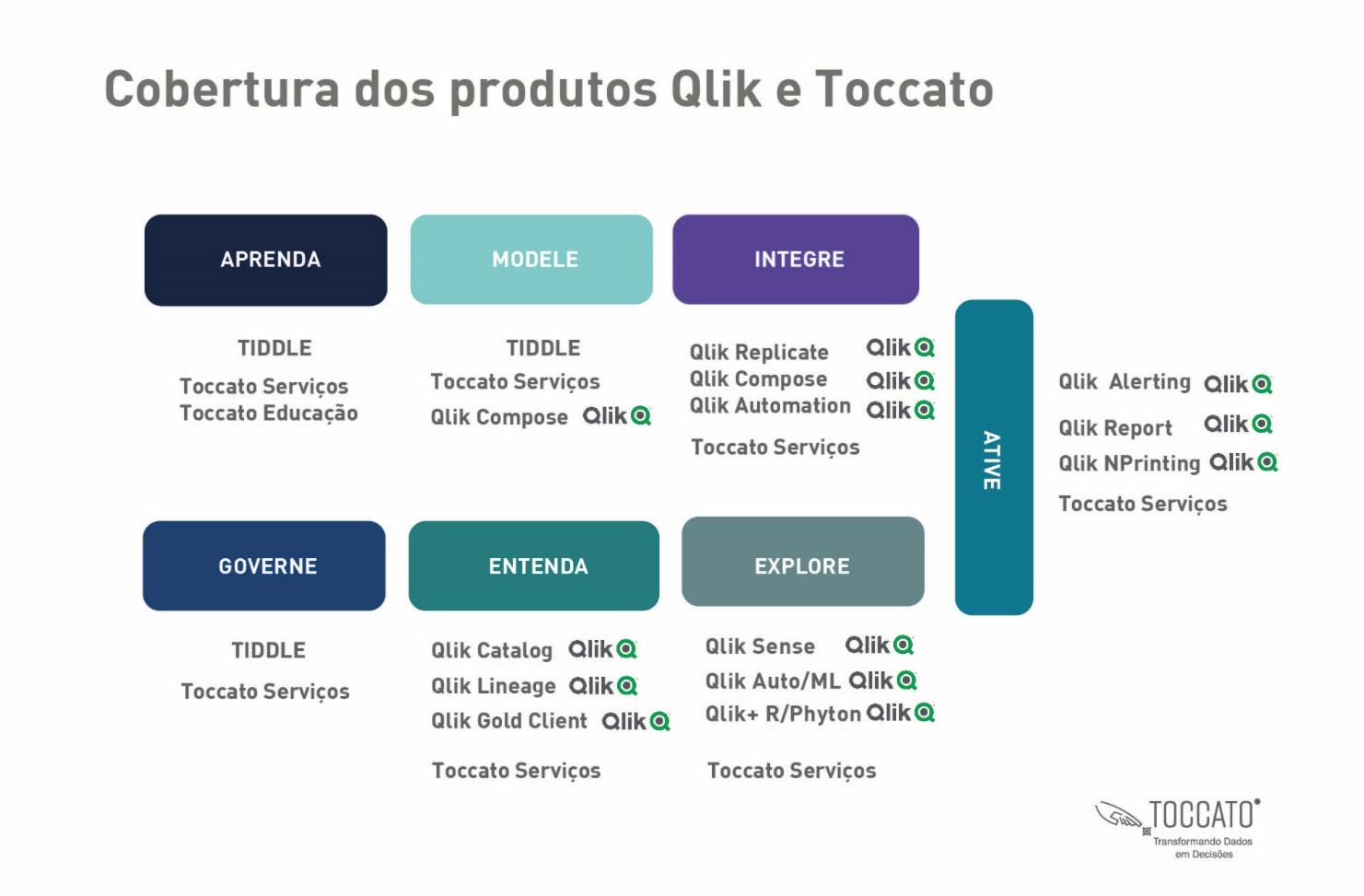
Criamos um framework completo para levar a organização em direção a ser cada vez mais data driven em ciclos iterativos.
Primeiro, estabelecemos o nosso Manifesto Data Driven com os princípios base que devem nortear todos os esforços data driven na organização.
Ative
Alertas + Relatórios Automáticos
Feedbak Transacional
Explore
Qualquer Pergunta
Inteligência Artificial
Entenda
Catálogo de Produtos
Proteção de Dados







Aprenda
Avaliação Contínua + Educação em Dados
Modele
Pilares de Dados
Cruzamento de Dados
Integre
Captura de Dados
Automações de Transformações
Governe
Tratamento Não Conformidade
Tratamento ROI
A primeira etapa do ciclo é o Aprenda. Aqui fazemos o assessment (avaliação por meio de prova eletrônica pela internet) dos conhecimentos de todos os usuários de negócio da organização em relação aos seguintes itens:
A segunda fase é o Modele. Aqui vamos identificar e construir os Pilares de Dados da organização e descobrir como eles relacionam-se entre si. Mas afinal, o que é um Pilar de Dados.
Assim como os pilares de um prédio sustentam toda a construção que pode ter dezenas de andares para cima, os Pilares de Dados são estruturas de dados, facilmente identificáveis na área de negócio, e que sustentam todos os esforços de data driven de uma organização.
Na construção civil, um pilar é construindo pela mistura de cimento, areia e brita montados num esqueleto de aço.

Já no universo de dados de uma organização, um Pilar de Dados é composto pela identificação de um Documento que existe no mundo real na vida daquela organização. São exemplos de documentos Pilares de Dados:
Nesta terceira fase do Ciclo Data Driven, vamos mapear e definir que esforços serão necessários para a Captura de Dados e Automação do Processo de Transformação e Carga de Dados.
Neste momento entram questões importantes como a frequência de extração de dados, a depender do caso de uso que precisamos atender. Há necessidades analíticas e de produção de insights que se acomodam muito bem com extrações de dados apenas diárias durante a madrugada (algumas vezes até mensais).
Contudo, dependendo da criticidade das análises envolvidas, muitas vezes pode ser preciso extrair os dados próximo do tempo-real para que já sejam analisados poucos minutos após sua ocorrência e planos de ação sejam executados para correções, adaptações e microestratégias que precisam ser implementadas muito rapidamente. A execução destas estratégias muitas vezes implica no ganho ou perda de milhões de reais em apenas um dia.
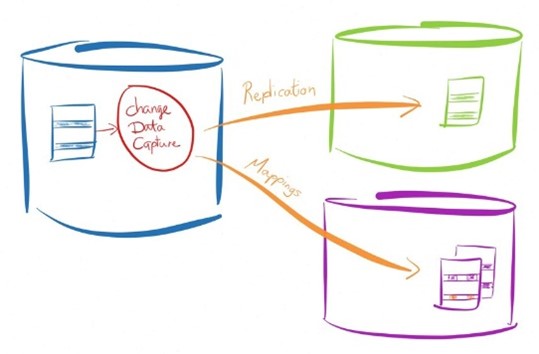
Se esse é o caso, será necessário então empreender esforços de Change Data Capture (Captura da Mudança de Dados) por meio de ferramentas de Replicação de Dados que leem as mudanças feitas pelos sistemas gerenciadores de bancos de dados e registradas nos Logs de Transação e replicam essas alterações para outros bancos de dados que serão usados para Analytics e Machine Learning.
Para completar, todo o processo de Transformação de Dados precisa de uma infraestrutura de Automação que possa não só coordenar a execução de cada uma das rotinas necessárias, como também interagir com diversos aplicativos (e.g. Teams, Salesforce, e-mail, etc) para fazer uma comunicação também automatizada e até a geração de dados e aplicações nas plataformas necessárias.
Essa automação é realizada por meio de ferramentas que permitem a construção de Fluxos de Automação gráficos que coordenam diversas tarefas e ferramentas envolvidas no processo.
Na fase Governe, nossa atenção está voltada para dois fatores importantíssimos para uma organização tornar-se cada vez mais Data Driven:
Depois de décadas de experiência na construção de projetos de Data Warehouse, Business Intelligence, Data Discovery e Analytics, observamos que um dos maiores inimigos para o uso em massa desse tipo de tecnologia entre os usuários de negócio é a credibilidade dos dados.
Isso ocorre sempre que os usuários encontram algum dado nos painéis de análise cujo valor não bate com o que ele encontra nos sistemas de gestão de onde aquele dado foi extraído. Isso pode ocorrer por três motivos:

Seja qual for o motivo, sempre que há um não batimento de dados entre os bancos de dados dos sistemas de gestão e do ambiente de Analytics, é de suma importância a abertura de um processo de Registro de Não-Conformidade.
Da mesma forma que acontece com a gestão da qualidade nas indústrias mais avançadas, esse processo de registro de não-conformidade precisa:
Somente assim conseguiremos preservar a qualidade dos dados e a confiança dos usuários de negócio, mesmo quando ocorrem erros nos tratamentos de dados.
Isso porque, quando o usuário percebe um não batimento de dados, é natural que passe a considerar todo o restante do ambiente de Analytics como suspeito. Imagine que você consulte seu extrato bancário num dia e observe que há um erro mostrando um saldo menor do que deveria. Se for comprovado que há um erro no extrato, você vai passar a desconfiar de todos os extratos daí para frente.
Se não houver uma explicação do que aconteceu que lhe convença, certamente você vai mudar de banco. É exatamente o que acontece com os usuários de negócio que, depois de observar alguns erros que não tratados ou explicados, acabam abandonando o uso do ambiente de analytics.
O outro lado desta moeda está na importância do registro de todos os retornos de investimento obtidos pelo uso do ambiente de analytics.
Depois de décadas desenvolvendo projetos para organizações de todos os segmentos econômicos e portes, já comemoramos com os clientes conquistas como:

O importante aqui é registrar todas essas conquistas de forma sistemática, inclusive com os respectivos valores em reais de cada um desses retornos de investimento. O que vemos é que essas vitórias são comemoradas, mas não ficam registradas em lugar nenhum e logo se perdem na memória ou viram lenda.
Então nesta fase, tratamos de providenciar um local estruturado para registrar não só esses grandes retornos, mas também os mais simples e de valor menor. Essa acaba sendo a base de impulsionamento para o patrocínio dos futuros projetos de analytics.
ma vez que os dados estão carregados, é fundamental entender o perfil de cada um de seus componentes. Para isso, temos dois esforços importantes a serem considerados:
É cada vez mais comum nas organizações a existência de diversos esforços, equipes e ferramentas em paralelo aplicadas no sentido extrair, transformar e disponibilizar dados para as áreas de negócio da própria empresa, mas também de seus fornecedores, clientes e parceiros.

Essa realidade acaba gerando um grande retrabalho na produção de informações e a falta de uma padronização, de metadados e de um depósito central onde um usuário possa acessar com confiança e credibilidade os dados da organização.
É nesse contexto que surge a necessidade de um Catálogo Central de Dados, onde possam ser armazenados conjuntos de dados interrelacionados e bem definidos com metadados completos. Esses conjuntos de dados também precisam ser pesquisáveis para que os usuários de negócio e também de TI possam descobri-los e publica-los na ferramenta de Analytics ou Data Science de sua preferência, como por exemplo Qlik, PowerBI ou Tableau.

Com o advento da LGPD (Lei Geral de Proteção de Dados) e de seus pares em outros países, a preocupação com o sigilo, governança e circulação do dado é um elemento cada vez mais presente.
Por isso, é preciso identificar se essas necessidades estão presente nos dados que circulam pela organização para garantir que essa circulação cause apenas o efeito benéfico esperado, sem comprometer a segurança e a privacidade das pessoas.
Aqui temos o momento alto de todo o Ciclo Data Driven. Tudo que fizemos até o momento servirá como fator estruturante para que o processo de Exploração dos Dados possa ocorrer de forma:
Tem que ser simples ou quase intuitivo para que seja manuseado pelo usuário de negócio de forma natural. Tem que ser flexível para permitir que qualquer pergunta seja feita de forma imprevista e a resposta seja obtida de forma instantânea. Tem que ser poderosa pois a resposta precisa vir quase que instantaneamente, não importando o volume de dados que está sendo consultado.
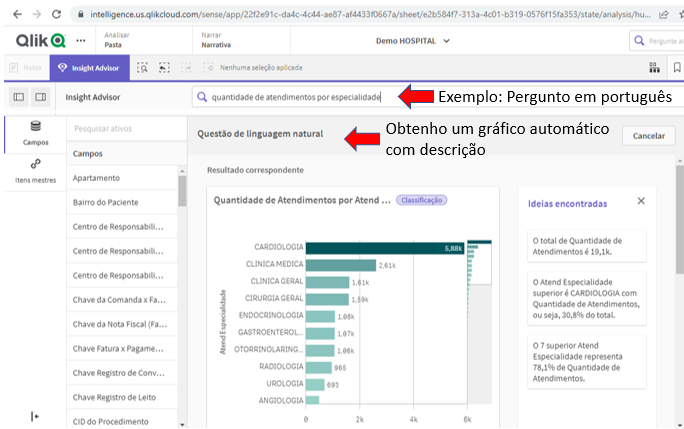
Essa é uma das principais estratégias para proporcionar ao usuário final poder de análise, simplicidade de acesso e flexibilidade para perguntar. Fazer qualquer pergunta significa manter uma sequência de perguntas de análise sem a necessidade de parar porque aquele dado não está disponível e se precisa pedir ao pessoal de TI que faça sua extração.
Isso é implementado por meio do Painel de Qualquer pergunta que permite ao usuário final de negócio saber tudo que precisa sem sair de uma única tela:
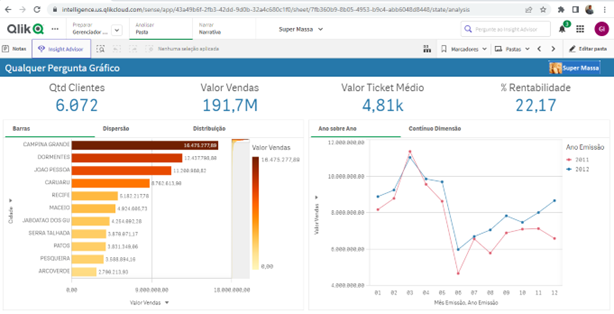
Esse é o painel onde o usuário conseguirá responder à qualquer pergunta por meio de gráficos combinados que permitem milhões de combinações diferentes sem sair de uma mesma tela.
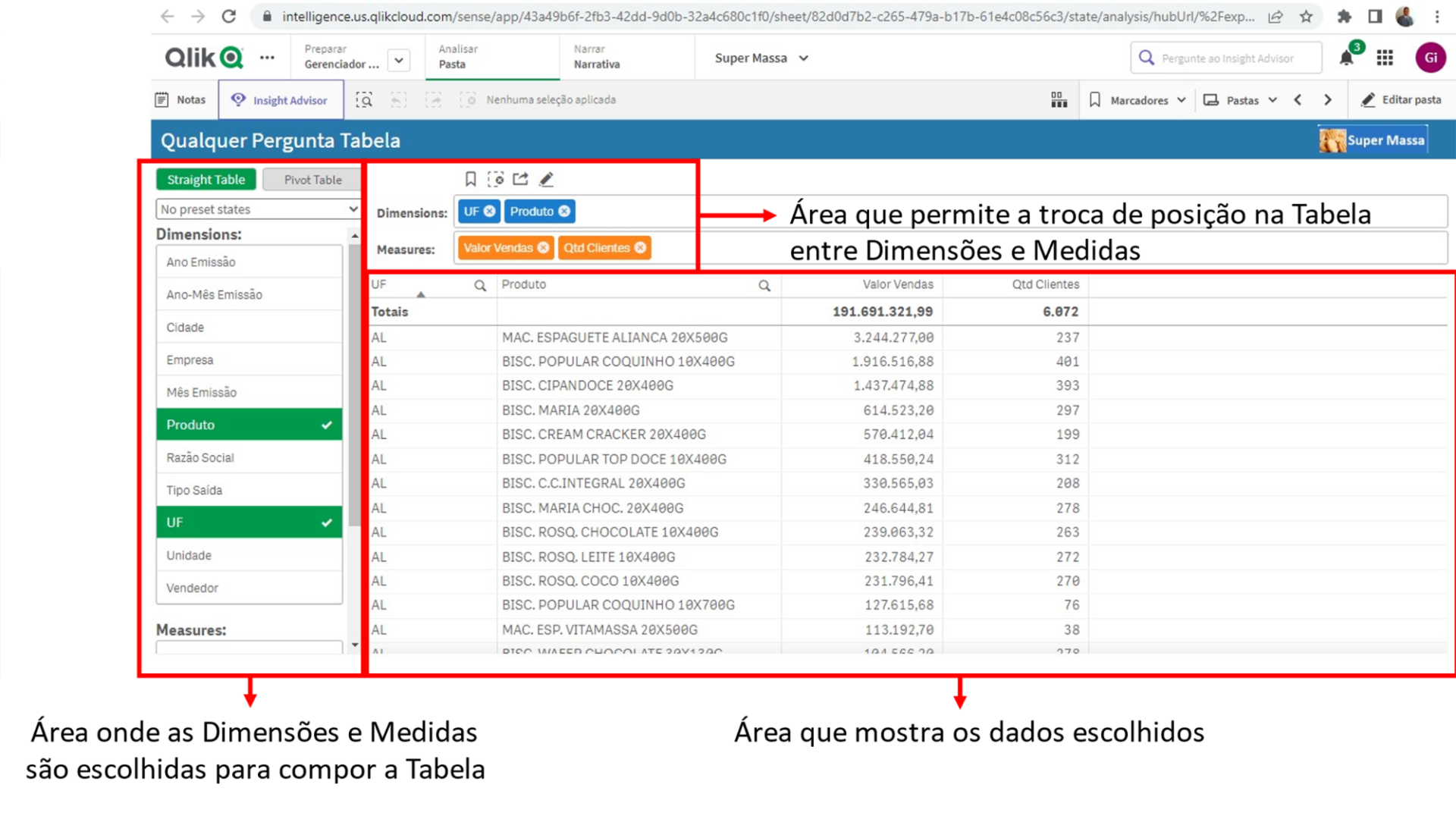
Veja a seguir as áreas do painel e suas funções. Inicialmente o painel está dividido em três grandes áreas:
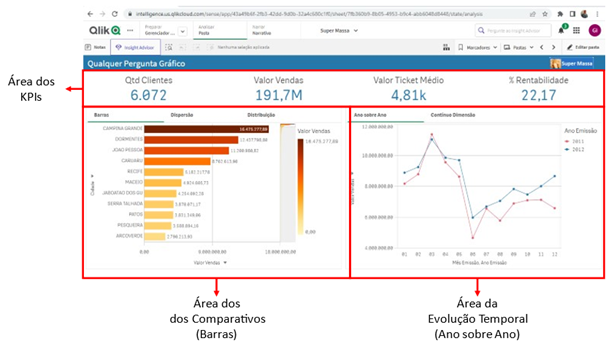
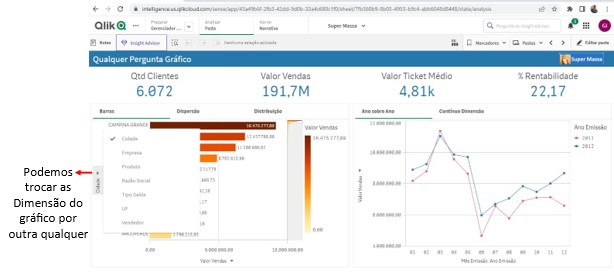
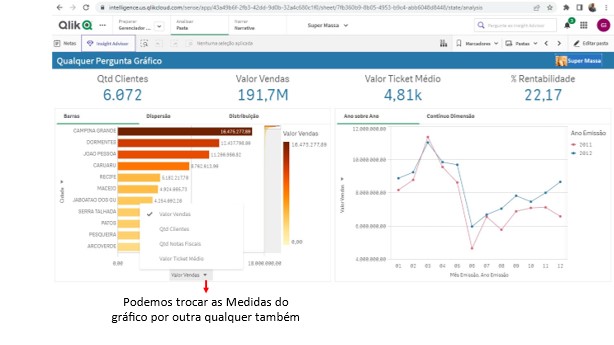
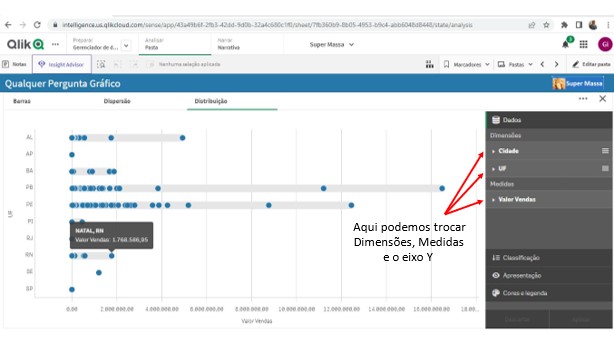
Nesta área temos a possibilidade de escolher que Dimensões queremos comparar e por quais Medidas vamos fazer essa comparação.
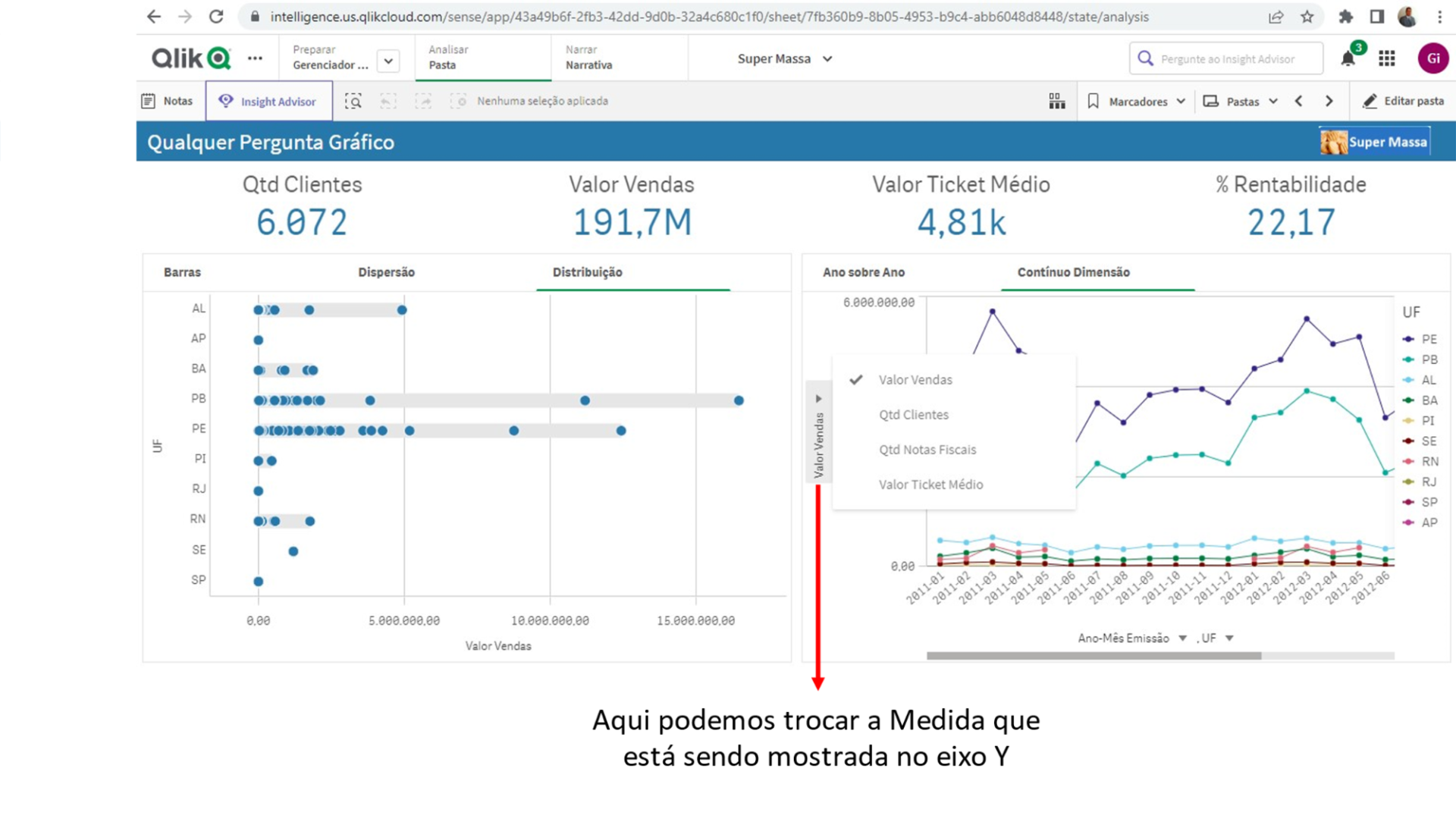
Veja que é possível trocar tanto a Dimensão como a Medida do gráfico por qualquer outra que faça parte do 5W2H deste Documento.
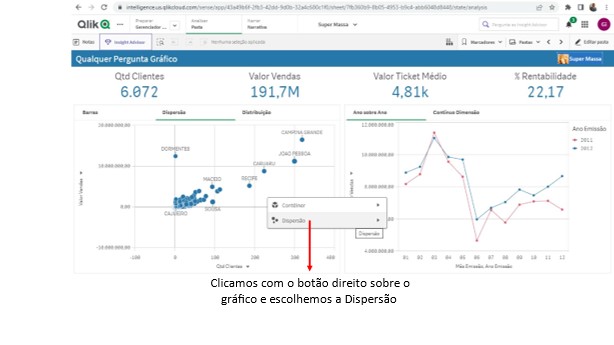
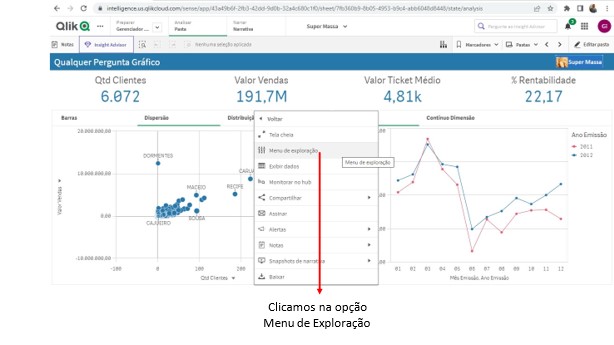
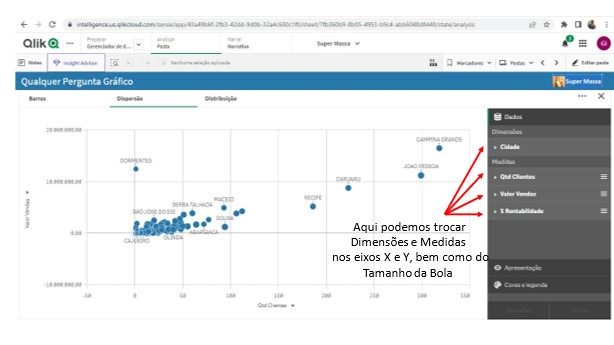
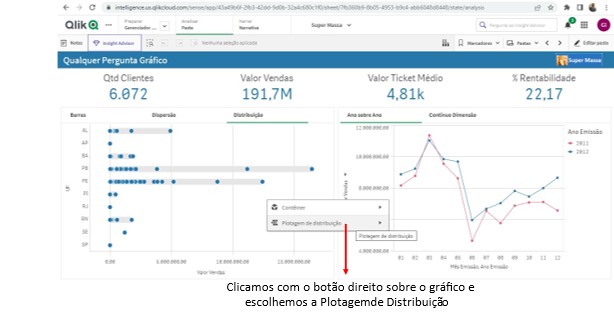
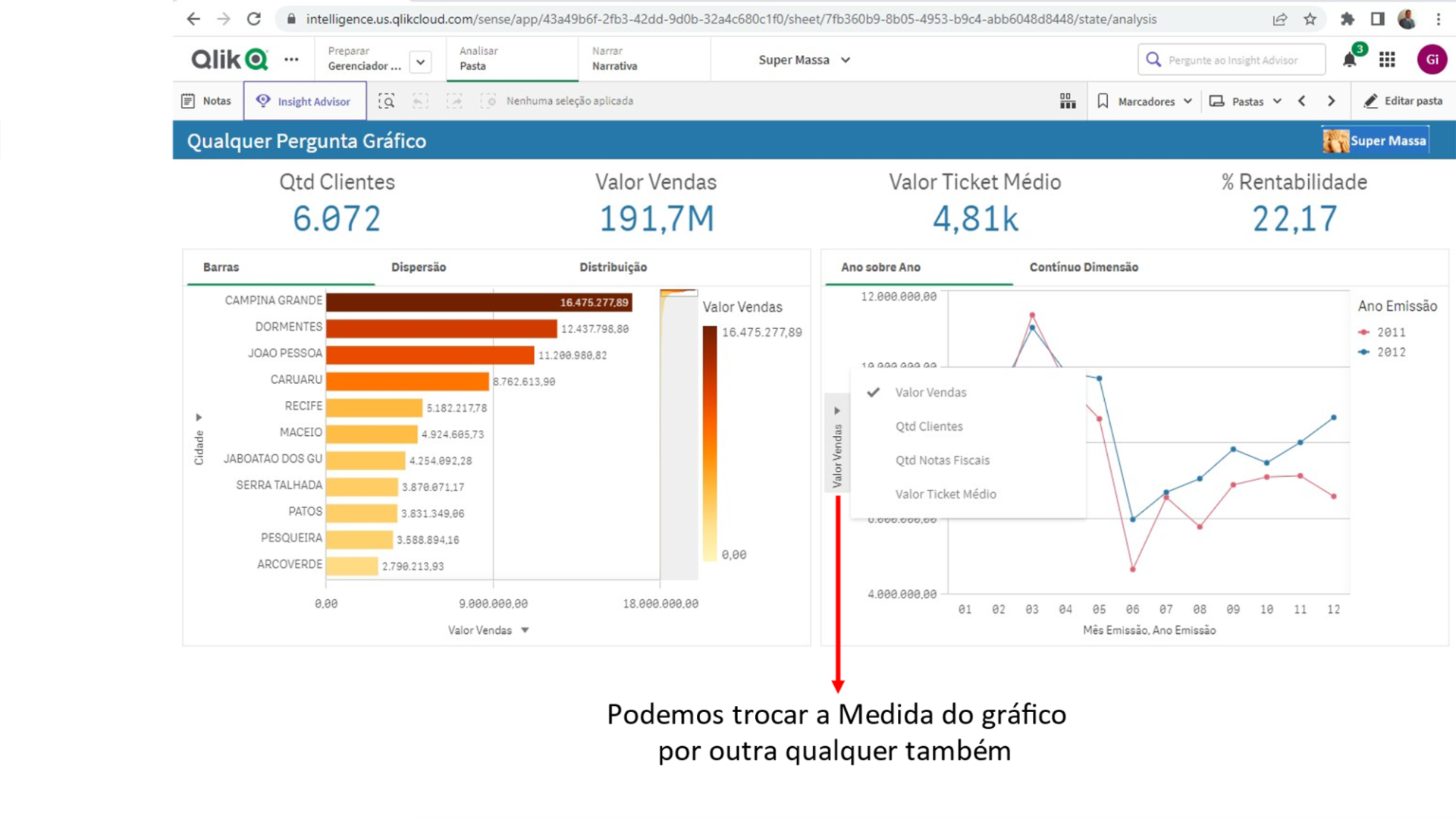
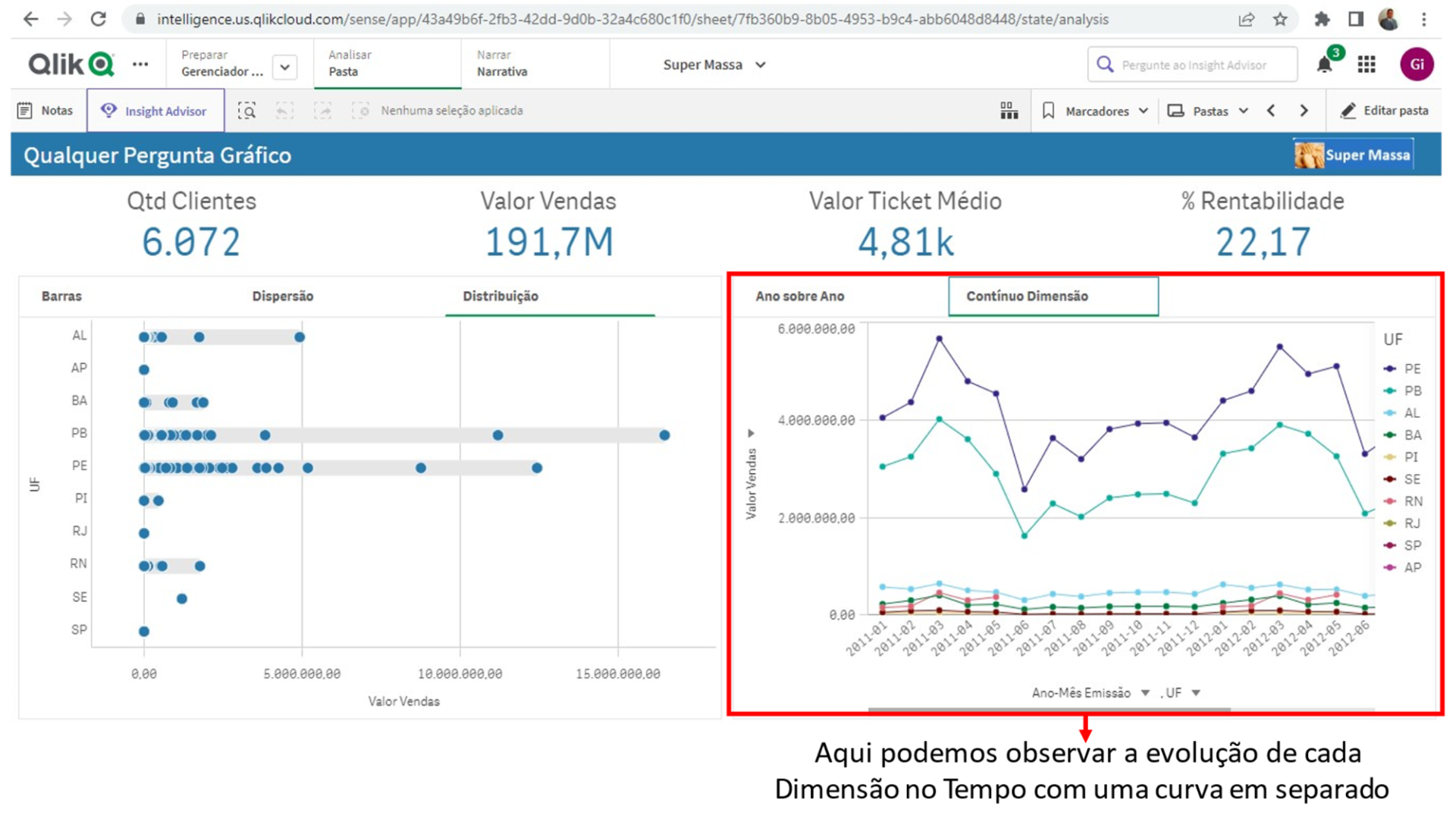
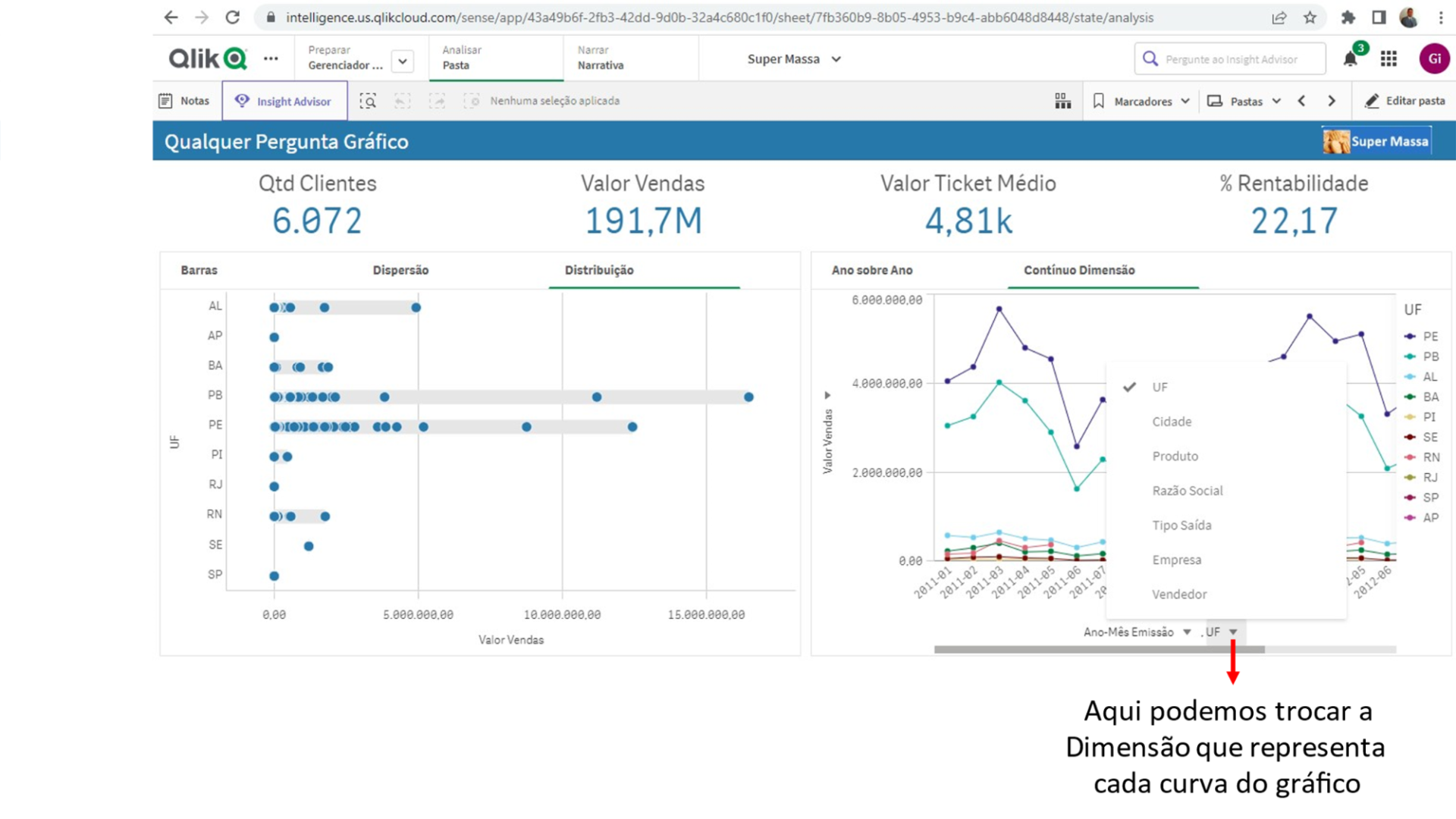
Nesta área temos a possibilidade de escolher que Dimensões e Medidas queremos ter a evolução temporal observada.
Veja que é possível trocar tanto a Dimensão (no gráfico Contínuo Dimensão) como a Medida do gráfico por qualquer outra que faça parte do 5W2H deste Documento.
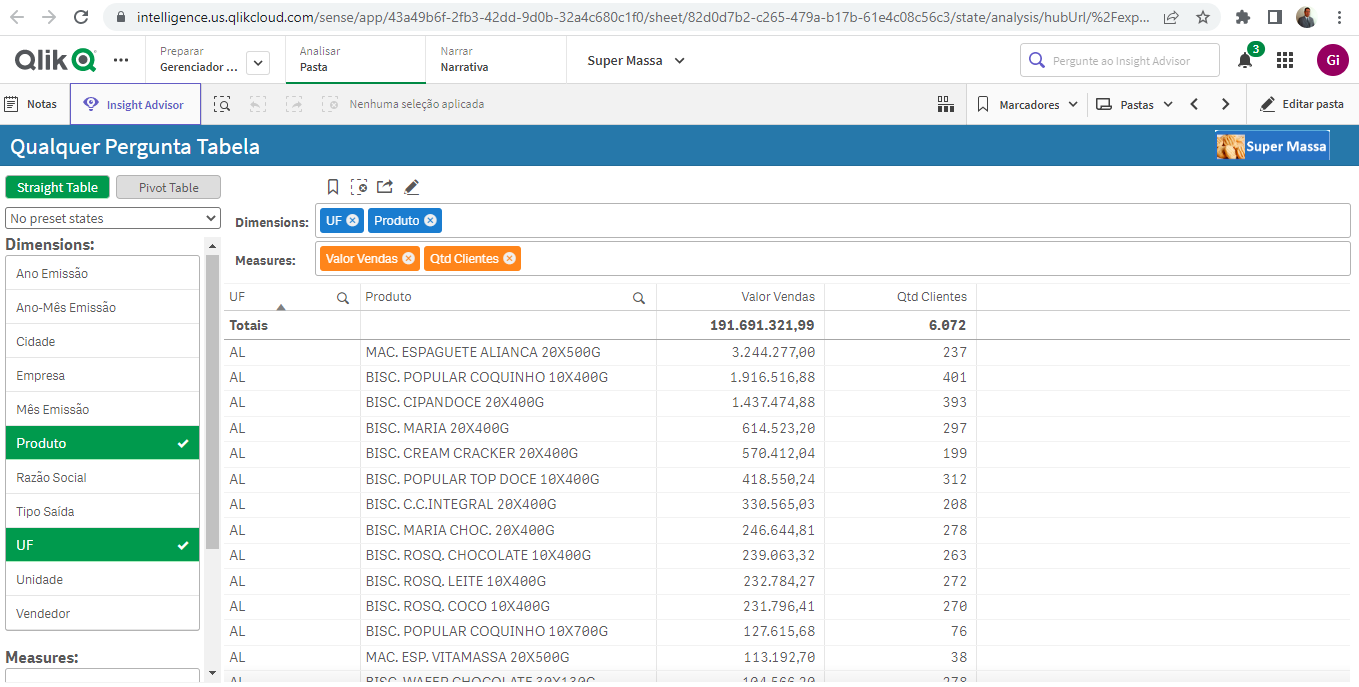
Sabemos que muitos usuários de negócio preferem ver os dados em Tabelas ao invés de gráficos. Principalmente as pessoas mais acostumadas a fazer análises em Planilhas Eletrônicas.
Por isso, temos também um painel de Qualquer Pergunta feito em forma de Tabela para deixar esses usuários de negócio mais confortáveis, onde podem escolher as Dimensões e as Medidas a serem utilizadas:
Vamos ver as áreas deste tipo de painel e a função de cada uma delas:
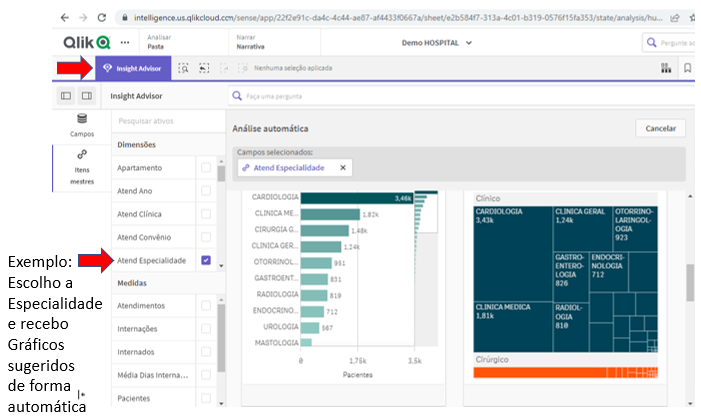
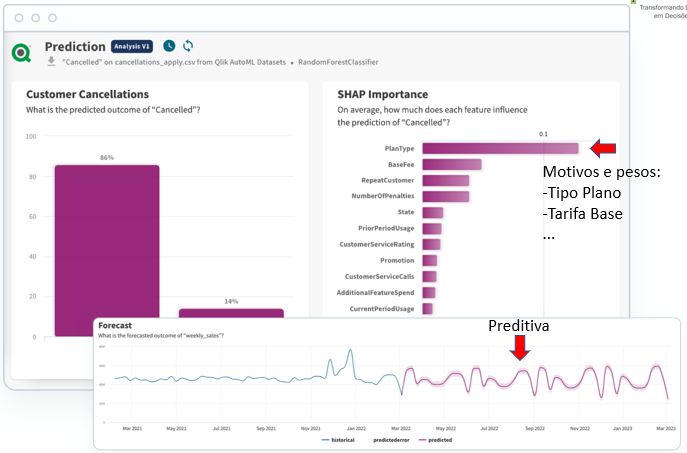
A fase de Ative busca identificar as oportunidades de que o ambiente de Analytics possa oferecer algo ao usuário de negócio de forma automática ao invés do tradicional que é o usuário buscar o que precisa navegando nos painéis.

Veja vagas abertas para nossos times, ou nos envie seu currículo pelo banco de talentos.
Calcule a sua maturidade em dados